Fragile Families Challenge Keras NN
wnowak10
I’ve not posted in some time…but the school year is winding down, so that means that my blogging should be winding up. I spent a lot of time working on the Fragile Families Challenge…and I detail some of my struggles in training predictive models on that data in this slideshow I drew up. Do check it out.
Some of the key points in that presentation:
- I did little to no feature engineering. Really, I only did two key preprocesses: 1.) I used median imputation to replace missing values, and 2.) I used SMOTE to balance the class imbalance.
- This training data was run through XGBoost, and it did ‘aight.
That is where we left off. As you can also infer from the presentation, I tried to do some elementary feature engineering, but it didn’t get my any improvements in my leaderboard score.
Thus, I’m here to try something new. Neural nets, of course. These can be a pain to train, so I want to try to document the process here for others to learn from (and for myself to reference in the future and take heart in when I have another training problem that just isn’t progressing!).
Training using vanilla Keras neural network
We have super wide data. I figured I’d try to make things as simple as possible, to start.
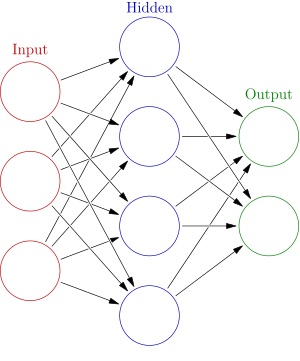
I connected each of the 14000+ inputs to a unique weight (using the model.add(Dense… functionality). (So there were 14000+ inputs, not just 3 as in image above.) Each input was hooked up to num_nodes number of hidden nodes (not just 4 as in image above). Then a linear combination of the activations from these hidden nodes were again linearly combined to generate prediction. I used regression, and not one hot…so the hidden nodes were combined and fed to just one final output node.
NN model code looked like:
# source activate py35
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressor
model = Sequential() # set up model
num_nodes = 4
model.add(Dense(num_nodes,
input_dim=x_tr.values.shape[1],
kernel_initializer='normal',
activation='relu'))
model.add(Dense(1, activation='sigmoid', kernel_initializer='normal'))
# X and Y are np arrays
model.compile(loss='mean_squared_error',
optimizer='adam')
fitt = model.fit( X, Y,
batch_size=52, epochs=num_epochs,
verbose=1, callbacks=None, validation_split=0.1,
validation_data=(x_val.values,y_val.values))
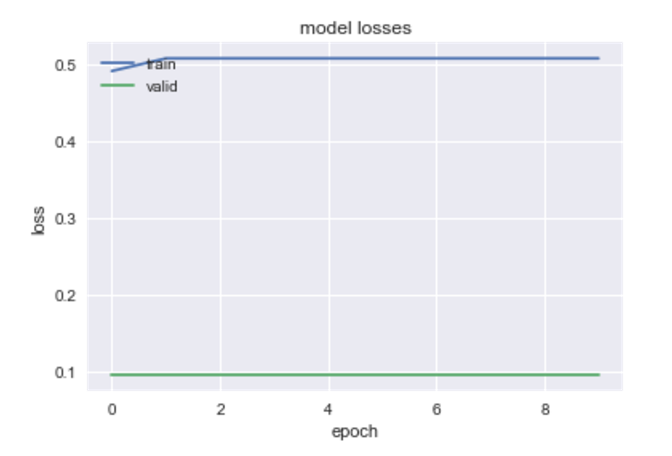
So that didn’t learn at all.
And the code for preparing the predictions dataframe looked like:
df_prediction_good_cols = df_prediction[x_tr.columns.values] # keep the columns that are in training data...
from fancyimpute import SimpleFill
filled = SimpleFill('median').complete(df_prediction_good_cols)
# use trained model to predict
preds = model.predict(filled,verbose=1)
Similarly, I tried for 4, 40, and 4000 nodes…and there was no progress. So it seems that a simple 1 layered model is not the way to go. (Or maybe the problem is just that we are only getting 0-1 outputs…how do I get some decimal action??)
Imbalanced train set
The above was with the balanced training set (with more observations for more classes). Maybe I shouldn’t do that? (This reminds me of the classic Seinfeld scene, which they unfortunately cut off before the great line “you’re not supposed to do that!”:)
Alas, with the imbalanced training set, we get none better…
What next?
So we’re still getting no success. What to try next?
- Perhaps we should standardize our features. Experts say this is pretty important, so let’s try it and see if it helps.
- Our models are flattening out in their learning pretty quickly…so we are getting suck in local minima (usually just a strategy of predict all 0). How can we avoid this?
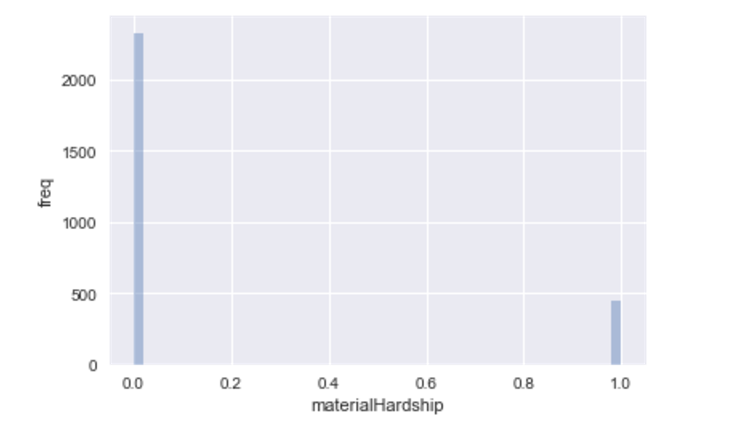
- We’ve yet to see our model output results other than 0 or 1. This makes me think I’ve simply made an error with my construction of the model. I could perhaps makes things easier and do 1 hot prediction. This probably makes the most sense, because material hardship is really a score out of 11. This would have the nice benefit of giving us predicted probabilities, instead of just values.
- Should we do deep learning? Adding layers? But how many?
So let’s try the above changes, and see if we can get our training data to over fit. Once we do that, perhaps we can back out a bit and find an optimum model. We’ll do this in another post.