Fragile Families Challenge Keras NN continued
wnowak10
At the end of last post, I proposed trying each of these ideas.
“So we’re still getting no success. What to try next?
- Perhaps we should standardize our features. Experts say this is pretty important, so let’s try it and see if it helps.
- Our models are flattening out in their learning pretty quickly…so we are getting stuck in local minima (usually just a strategy of predict all 0). How can we avoid this?
- We’ve yet to see our model output results other than 0 or 1. This makes me think I’ve simply made an error with my construction of the model. I could perhaps makes things easier and do 1 hot prediction. This probably makes the most sense, because material hardship is really a score out of 11. This would have the nice benefit of giving us predicted probabilities, instead of just values.
- Should we do deep learning? Adding layers? But how many?”
So let’s try to resolve these 1 at a time. First, let’s look at the third point above. I just want to make sure this architecture is capable of output other than 0 or 1.
Gettin’ some decimals??
I made some new dummy data…and tried to see if Keras regressor model would at least work there.
Below, I code X as a sequence from [0, 1, 2, ….100]. Y is predicted by a sigmoid function, as follows.
That is:
y = 1 / 1+e^-x
A plot looks like:
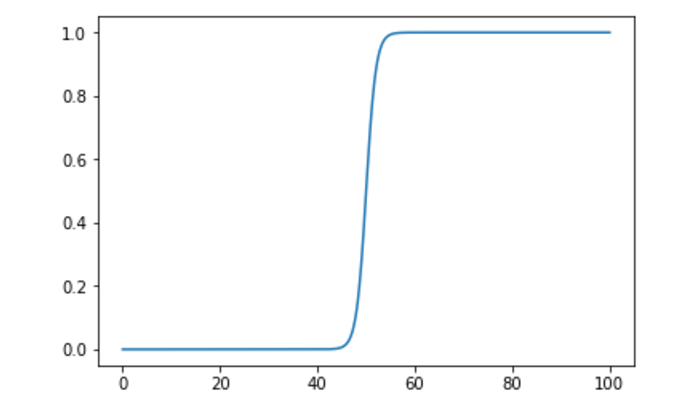
When I do this, I train a model that makes a) good predictions, and b) predictions besides 0 and 1. So the model architecture is OK…so WTF is wrong with my FFC model?
To see the code for the demo, see github.
It is always both annoying and gratifying when you run a simple proof of concept test, and it both works and doesn’t. My toy code above did what I wanted it to do. It learned a sigmoid model, and made appropriate output predictions (values between 0 and 1). BUT, this is annoying, because I don’t then know why my FFC model is not doing just that.
Even more perplexing, if the model weren’t learning it all, I’d think it would just spit out 0’s. But the previous post showed that there are some outputs of 1. Why? There are no y value’s of 1 in the training set, so it makes little sense to me that the model would learn to predict y = 1 in the prediction set. Hmmm…
Anyways, I’ll look into other problem solving approaches in another post, in an effort to keep these things relatively brief and bite-size-able.