Fragile Families Challenge Keras NN continued - One Hot instead of regression?
wnowak10
So this is a continuation of a post about my efforts to train a neural network to solve the Fragile Families challenge. In previous posts, I explained how my current models just weren’t working well.
Since I am trying to predict a measure of poverty which is derived from 11 survey questions, maybe it would make better sense for the model to predict 11 outputs, each representing, perhaps, a softmax probability…this seems like it could be more sensible and interpretable than a plain, 1 output node, regressor neural network. It also seems like a good idea since the former one just hasn’t been working. So let’s try to make these changes and discuss in this blog post!
This entails taking an input (in this case a poverty score on a 0 to 11 scale) and converting said input into a sparse vector with a 1 at the appropriate index and 0’s everywhere else. So the number 2 would be converted to [0, 0, 1, 0, 0,…] (because of 0 indexing, 2 is in the 3rd slot).
The code to make this all happen is here. I use softmax activation, which should predict probabilities…curiously, when I finally make predictions, I don’t get that, so that is something that remains to investigate.
Hearteningly, though, this method is resulting in better looking results. A quick training round that stopped due to overfitting shows the following in my prediction set:
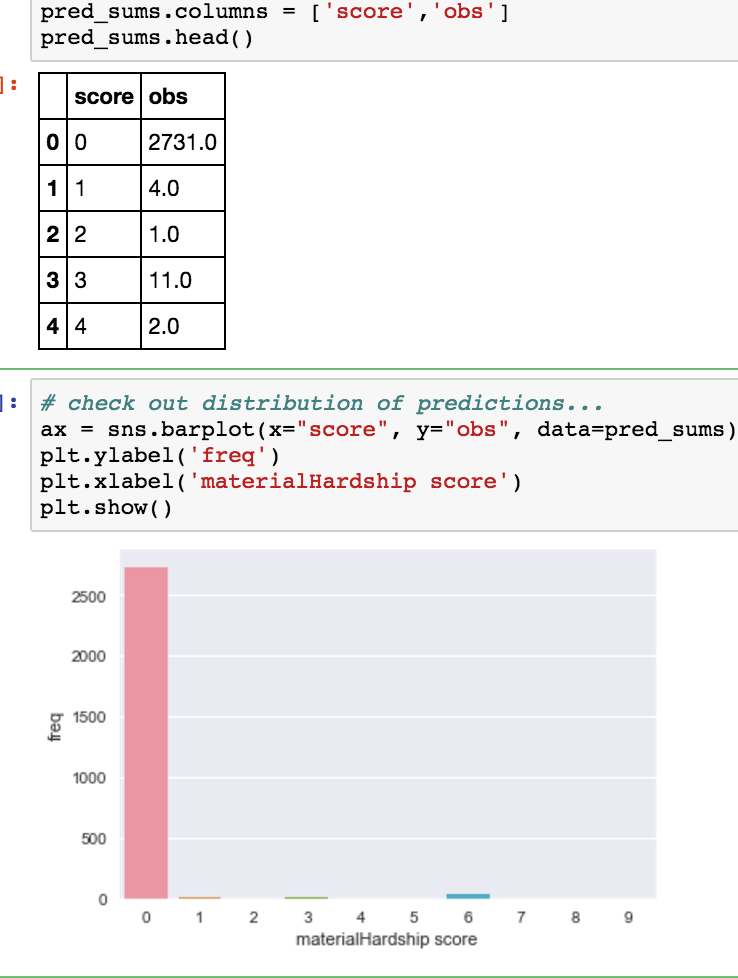
The code to make this all happen can be found in this ipynb.
SO, I need to figure out why the softmax is not predicting probabilities…but this approach (due to the better variance in my prediction set outcomes) seems more promising, so let’s stick with it going forward.